


알고리즘이란, 특정 일을 수행하는 유한한 명령어셋을 말한다.
이번엔 그 중 하나인 sorting algorithm을 알아보자.
Sorting Algorithm이란 리스트의 요소들을 특정 순서로 재배치하는 것이다.
이렇게 함으로서 많은 문제들은 쉽게 풀린다. 예를들어,
■ 리스트에서 특정 값을 검색
■ 리스트에서 최소/최대 또는 k번째 최소/최대 값 찾기
■ 특정 값 테스트 및 리스트에서 중복 삭제
■ 특정 값이 나타나는 횟수 카운트
이와 같은 문제들을 쉽게 해결할 수 있다.
순차적으로 재배치하는 방법(알고리즘)은 여러가지가 있는데
비교할것인지 비교하지 않고 재배치할 것인지, 반복적인지 재귀적인지 등의 방법을 따진다.
그냥 재배치하기만 하면 됐지 굳이 여러 방법을 따지는 이유가 뭘까?
각각의 알고리즘은 자신만의 고유한 이점과 한계가 있기 때문이다.

이따가 설명할 시간복잡도와 관련한 방식과 이점이 있다.
우선 bubble sort와 selection sort에 대해 알아보자.
Bubble sort

솔직히 감동했다. 이런 움짤까지 가져와서 학생들의 이해를 도와주실 줄이야.
이 교수님은 살짝 강의에 진심이시구나 싶었다. 영어강의라 전부 알아듣진 못했지만 맥락상 이해만 하면 됐지.
아무튼 버블정렬에 대해 설명하자면 반복적으로 인접한 요소들과 비교해서 swap해주는 알고리즘이다.
예를들어보자

맨 처음 인덱스 7은 두 번째 인덱스 4와 비교하고 순서를 바꾼다. 다음은 두 번째 인덱스가 그 다음 인덱스와 비교하고 순서를 바꾼다. 이렇게 쭉~ 한 번의 순회를 마친다. 이걸 인덱스의 숫자만큼 8번 반복한다.
Selection Sort

음~ 아주 좋다. 역시 움짤이 이해가 쏙쏙된다. 사실 이 경우는 짤만 봐선 무슨 소리를 하는지 모를 수 있다.
selection sort는 가장 작은 요소를 반복적으로 선택해서 그 값을 임의의 변수에 저장한 후, for문의 회차가 끝나면 그 값을 가장 앞으로 보내는 정렬이다.

맨 처음 인덱스인 7을 임의의 변수 min에 저장하고 다음 list에 저장되어 있는 요소들을 쭉~ 둘러본다. 2번째 인덱스인 4와 비교했더니 더 작다? 그럼 min에 7 대신 4를 저장해주고... 쭉 반복해주면? min 값에는 1이 들어가있다.
이렇게 한번의 회차가 끝났으면 가장 첫 번째 인덱스에 min값을 저장해준다.
여기서 알 수 있는 점이 있다.
버블정렬은 반복적으로 인접 요소와 swap해준다는 것.
선택정렬은 반복적으로 가장 작은 요소를 옮긴다는 것.
그럼 딱 보기에 어떤 알고리즘이 더 괜찮은 알고리즘일까?
이걸! 확인하기 위해 우리는 복잡도를 배운다.
알고리즘은 어떻게 평가되는 것일까?
과연 이 알고리즘이 효율적으로 동작 할것인지 확인하는 과정에서 좋은 알고리즘이라 평가한다.
그래서 알고리즘이 동작하는 데에 얼마나 시간이 걸리는지 running time으로 측정하고 그 시간을 바탕으로 복잡도를 분석한다.
그럼 여기서 얘기하는 알고리즘의 시간 복잡도가 뭘까?
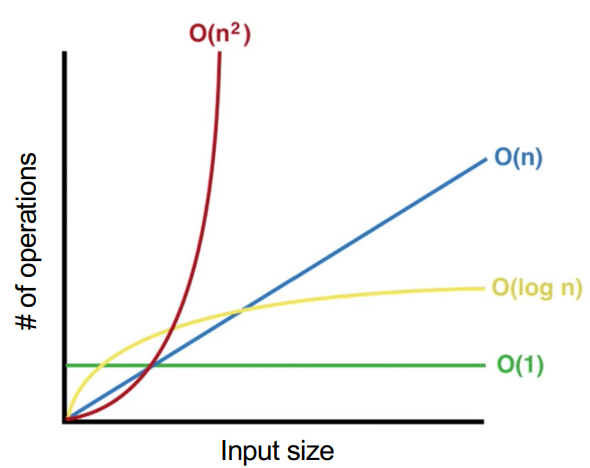
함수가 입력된 길이가 길수록 프로세스를 마칠 때까지 걸리는 시간의 양은 늘어난다.
그럼 주요 명령어나 연산의 개수가 줄어든다면? 프로그램은 그 만큼 빠르게 실행된다.
예를 들어 버블정렬 연산의 슈도코드를 살펴보자.

여기서 첫 번째 for loop 부분의 비용을 c1이라고 하자.
그리고 두 번째 줄의 for loop 부분의 비용을 c2, if문은 c3, 할당문은 c4, 마지막으로 return문은 c5로 생각하자.
이 정렬 연산의 전체적인 비용은 c1을 n만큼 반복했기 때문에 c1 * n,
비용 c2를 그 안의 연산 ∑(t ) 만큼 반복했기 때문에 c2 * ∑(t ) (여기서 ∑(t )는 for루프가 실행된 명령어t의 갯수 ),
if문은 c3 * ∑(t − 1), 할당문은 c4 * ∑(t − 1), 마지막으로 return문은 비용 c5에 한번 실행됐으므로 c5 * 1
즉, 전체적인 비용은 c1 * n + c2 * ∑(t ) + c3 * ∑(t − 1) + c4 * ∑(t − 1) + c5 이다.
그럼 여기서 ∑(t ) 은 어떻게 계산해야 하는 걸까

아까 예시에서 한 회차가 정렬됐을 때를 생각해보자. (bubble sort)
리스트에서 n개의 요소가 있는 경우, 바꾸고 바꾸다보면... n - 1번의 연산이 이루어진다. (혹시 왜 n이 아니라 n-1인지 이해가 안가면 element 7개중 인접 요소와 swap하는 연산은 6번 밖에 없기 때문이다.)
그럼 첫 번째 회차에선 n - 1, 두 번째에선 정렬 된 요소가 2개이니 n - 2,,,, 이렇게 (n - 1) + (n - 2) + ... + 1까지 더해주다보면 결국 n * (n - 1) / 2 가 되고 우리는 앞으로 Big-O 표기법을 사용하여 O(n^2)라고 표현할 것이다.
Selection sort도 마찬가지이다. 한번 쭉 순회해서 min에 할당할 변수를 찾고 (대략 n번 비교)
그걸 n번 반복하니, 선택 정렬도 O(n^2)의 시간 복잡도를 갖는다.
'ps > 자료구조, 알고리즘' 카테고리의 다른 글
| Quick sort 소개 (0) | 2024.04.05 |
|---|---|
| 왜 두 알고리즘을 합친 MergeInsert sort 를 사용해야 할까 (c구현) (0) | 2024.04.05 |
| Divide and Conquer의 재귀문제를 공식으로 풀기 (0) | 2024.03.26 |
| Insertion sort, merge sort 소개와 시간복잡도 구하기 (c구현) (0) | 2024.03.21 |
| 점근 표기법 (Big-O, Omega, Theta) (0) | 2024.03.17 |