

Machine Learning에서 데이터를 분류하는 방법
Scikit-learn 으로 embedding을 어떻게 활용할 수 있을지 알아보자,,, (맛보기)
(사이킷 러닝은 파이썬 기반 머신러닝 라이브러리)
우선 보유한 학습 data를 기반으로 문제를 설정해야 한다.
이 단계에선 문제에 어떻게 접근할지 접근 방법을 결정한다.

data type에 따라 머신러닝 문제를 판별하는데, discrete와 continuous에 따라 label을 구별한다는 것이 무슨 말이냐면
0, 1 이렇게 딱딱 떨어지는 것처럼
예를들어 자동차 레이블, 비행기 레이블로 나누는 경우 discrete하며
분류 방식으로 접근한다. (관리-감독 학습)
반대로 continuous한 label의 예시로, 자동차의 속도는 0과 1같은 값이 아니라 계속해서 변화할 수 있다.
아니면 비행기의 연료 소비율이나 엔진 출력 등도 연속적인 값이다.
이 경우 회귀방식으로 접근한다.
만약 data에 label이 없다면 clustering 방식으로 접근한다. ( Dimensionality Reduction 등등.. )
Classification 접근

학습시킨 데이터셋의 분포와 레이블에 따른 결정 영역 (decision boundary)을 생성한다.
data에 discrete한 label이 있다.
Regression 접근

data에 continuous한 label이 있고, 연속적인 입력데이터에 Fitting 되는 함수를 예측한다.
정의역과 치역을 디자인할 수 있는 함수 디자인이다. 데이터에 노이즈가 섞여있을 때 진짜 데이터를 어떻게 찾아가는지가 관건이다.
회귀 접근에서는 주로 입력 변수와 출력 변수(연속적인 값) 간의 관계를 모델링하고 예측하는 것이 주요 목표이다.
Clustering 접근
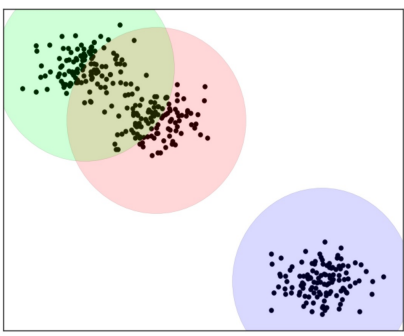
Unsupervised Setting에서 입력 데이터의 패턴이나 군집 (Cluster)를 계산한다. data의 label이 없는 경우 필요한 접근이다.
Classification 과 비교해보면 확실히 Discrete한 영역이 아니긴 하다.
머신러닝으로 임베딩을 활용하는 과정

우리가 학습시킨 데이터들(아마도 문장이겠지)이 있을테고, 이 문장을 임베딩으로 변경해주는 작업을 gpt를 통해 제공받은 후, 우리는 이것을 어떻게 활용할것인가에 대해 배우고 있다.
위 그림은 레이블이 있는경우, 아니면 없는경우 어떠한 알고리즘을 활용할것인지에 대한 순서도이다.
Scikit-learn (라이브러리)에 있는 알고리즘을 가져와서 알고리즘을 선택하고, 그에따라 데이터들을 학습시킨다면
새로운 데이터들이 들어왔을 때 예측값을 뽑아내는 방식이다.
Scikit-learn에는 수많은 알고리즘이 있는데, 이들 중 어떤 것이 Classification, Regression, Clustering 에 사용되는 알고리즘인지 파악하고 사용하면 된다.
머신러닝 모델의 성능 평가 방법 - 교차검증
이렇게 수많은 모델들을 알아봤는데, Scikit-learn에 있는 기능 중 하나인 Supporting knowledge을 통해 머신러닝 모델의 성능을 평가할 수 있다.
머신러닝 모델은 일반적으로 데이터를 train data set와 test data set로 나누어 모델을 훈련하고 평가한다. 그러나 이러한 방법은 test data에 대해 일반화할 수 없는 편향된 성능 예측을 초래할 수 있다.
그래서 이러한 문제를 해결하기 위해 Supporting knowledge는 Cross-Validation (교차검증)을 사용한다.
머신러닝 모델을 돌리기 위해 많은 데이터를 모으기가 쉽지 않을텐데 (Scikit-learn 에 따르면 보통 100K)
교차검증은 전체 data set의 비율을 나눠서 예측결과를 판단하기 때문에 데이터가 적을수록 교차검증이 유용하게 쓰인다.

그림 예시가 조금 헷갈리게 나와있는데, 이 경우는 하나의 model을 5등분하고
CV1에서는 1번째를 test data로, CV2에서는 2 번째를 test data로 설정해서 전체 CV Error를 수집하는 것이다.
위 그림의 경우 5 Fold CV Error = (CV1 Error + CV2 Error+ CV3 Error+ CV4 Error+ CV5 Error) / 5
교차 검증은 다음과 같은 단계로 수행된다.
- 데이터 분할: 먼저 데이터를 여러 개의 부분(폴드)으로 나눕니다.
일반적으로 k-겹 교차 검증(k-fold cross-validation)에서는 데이터를 k개의 폴드로 나눕니다. - 모델 학습과 평가: 각 반복에서 하나의 폴드를 선택하여 테스트 세트로 사용하고, 나머지 폴드를 훈련 세트로 사용하여 모델을 학습합니다. 이렇게 하면 k번의 모델 훈련과 평가가 이루어집니다.
- 성능 측정: 각 반복에서 모델의 성능을 측정하여 평균 성능을 계산합니다. 일반적으로 평균 정확도나 평균 손실과 같은 평가 지표를 사용합니다.
- 모델 선택: 다양한 하이퍼파라미터 조합 또는 모델 간의 성능을 비교하여 최적의 모델을 선택합니다.
예전에는 데이터가 많지 않던시절엔 교차검증이 항상 사용됐었는데, 딥러닝이 나오고 모델의 데이터가 많아진 이후로는 교차검증이 필수로 쓰이지는 않게 됐다고 한다.
Underfit, Overfit
교차 검증 이후에 모델을 선택할 때, 모델의 parameter별 양상의 변화가 나타난다.

여기에서 파란색 선이 예측한 값이고 초록색 선이 실제 True data 값이다. 빨간 점은 noise data를 의미한다.
위 그래프에서 예측값의 차원이 너무 낮아서 (y = ax + b 같이 parameter가 너무 적어서)
실제 참값 data와 차이가 나는 경우를 Underfit이라고 한다.

반대로 예측값의 차원이 너무 커서 차이가 나는 경우는 Overfit이라고 한다.
이러한 오버핏 언더핏의 예시로 k-Nearest Neighbor Classification가 있다. (그냥 분류기임)
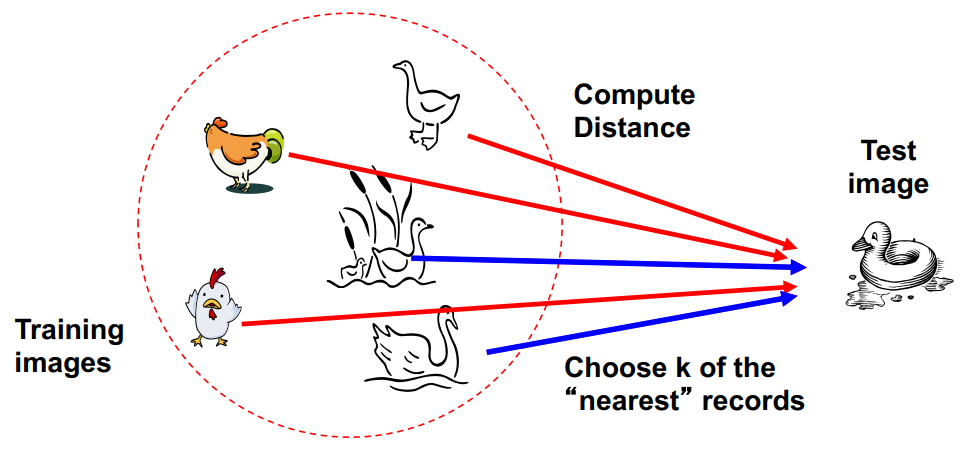
이 분류기는 가장 가까운 training data 포인트의 라벨을 K개 만큼 각 테스트 데이터 포인트에 할당한다.

만약 k 값이 너무 작으면 노이즈 포인트에 민감할 것이고 (오버핏), 반대로 너무 크면 이웃에 다른 클래스의 포인트가 포함될 수있을 것이다. (언더핏)

왼쪽 오버핏 그림처럼 noise까지 결정영역에 들어갈 수도 있고,
오른쪽 언더핏 그림처럼 noise가 너무 섞여서 분류기가 작동하지 않을 (학습 data를 못맞춤) 수도 있다.

정리하자면
Underfitting : 모델이 모든 관련 클래스 특성을 표현하기에는 너무 "단순"하다.
- 높은 편향 Bias과 (일반적으로) 낮은 변동 Variance
- 높은 training 오류와 높은 테스트 오류
Overfitting : 모델이 너무 "복잡"하고 관련 없는 특성(noise)에 맞춰져있다.
- 낮은 편향 Bias 및 (일반적으로) 높은 변동 Variance
- 낮은 training 오류와 높은 테스트 오류
여기서 Variance와 Bias에 대해 모델 입장에서 보면

Variance란, 약간의 데이터 변화에 모델이 크게 반응하는가를 본다. (낮은게 좋음)
- High variance: Overfit (보통 low bias)
- Low variance: Underfit (보통 High bias)
Bias란, 모델이 특정한 형태에 Biased 되어 있는가를 본다. (낮은게 좋음)
아까 예시에서 Variance 와 Bias가 Trade-off 관계임을 알 수 있는 그림이 있었다.

특정 순간을 기점으로 testing loss가 급격하게 증가하는 구간이 있는데, 우리는 Testing (Validation) Loss를 보며 빠르게 Stop을 해야 한다.

추가) Curse of Dimensionality

임베딩으로 벡터화시킨 데이터에서 가까운 데이터를 꺼내야 하는데 차원이 커질수록 만나기 어려워진다.
위 그림처럼 search할 영역이 점점 넓어지기 때문인데, 이 문제를 해결하기 위해서
차원을 줄이거나, LASSO 와 같은 정규화를 시켜야 한다.